Power Automate Desktop「OCRを使ってテキストを抽出」アクション
画面や画像の文字列を読み取り、
Power Automate Desktopで扱えるテキストデータに変換するアクションです。
利用方法と日本語追加の方法を紹介します。
利用方法
「アクション」の「OCR」より「OCRを使ってテキストを抽出」をドラッグします。
パラメータの設定画面が表示されるので値を指定します。
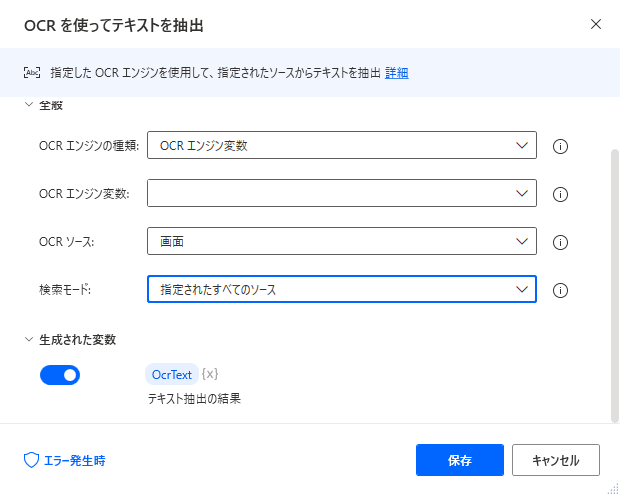
パラメータ
OCRエンジンの種類
※2021年12月のアップデートで「Windows OCR エンジン」 が追加されました。
「Windows OCR エンジン」か 「Tesseractエンジン」を指定します。
(OCRエンジン変数は廃止されました)
「Windows OCR エンジン」の方が設定の手間が少ないため、基本的にはこちらを推奨します。

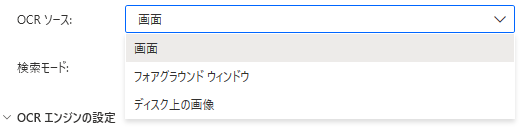
OCRソース
テキストを読み取る対象を指定します。
「ディスク上の画像」の場合、画像のパスも指定します。
(画像がメインになると思われます)
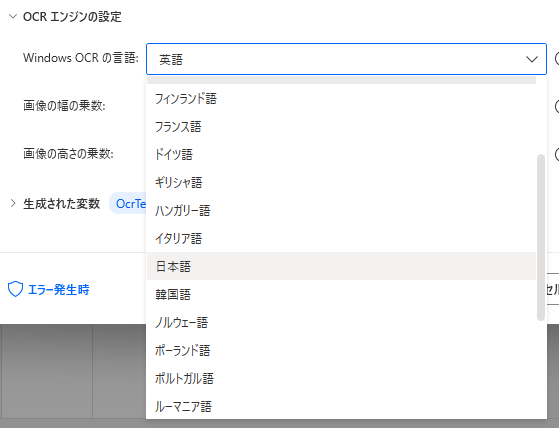
Windows OCR の言語
「Windows OCR エンジン」の設定です。
追加設定なしで日本語を利用可能です。
他の言語を使う
「Tesseractエンジン」の設定です。
英語、ドイツ語、スペイン語、フランス語、イタリア語以外であればONにします。

言語コード
「Tesseractエンジン」の設定です。
英語、ドイツ語、スペイン語、フランス語、イタリア語以外の場合に指定します。
日本語を指定する場合はjpnを指定します。

言語データパス
「Tesseractエンジン」の設定です。
jpn.traineddataとjpn_vert.traineddataをダウンロードし、
その2ファイルを保存したディレクトリを指定します。


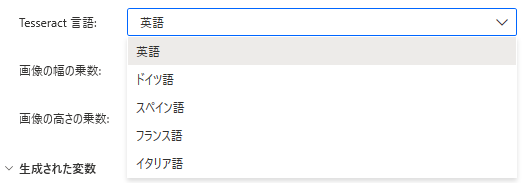
Tesseract言語
「Tesseractエンジン」の設定です。
英語、ドイツ語、スペイン語、フランス語、イタリア語の何れかであれば
この中から指定します。(他の言語を使う、がONの場合は表示されません)
画像の幅・高さの乗数
高解像度の画像や画面の場合、調整します。

生成された変数
アクションの結果が格納されます。この変数名は変更可能です。
同一アクションを複数、使用する場合は、どのような値かを示す名前に変更推奨です。

OcrText
読み込んだテキストが格納されます。
Power Automate Desktopを効率的に習得したい方へ
当サイトの情報を電子書籍用に読み易く整理したコンテンツを
買い切り950円またはKindle Unlimited (読み放題) で提供中です。

Word-A4サイズ:1,700ページの情報量で
(実際のページ数はデバイスで変わります)
基本的な使い方から各アクションの詳細な使い方、
頻出テクニック、実用例を紹介。(目次)
体系的に学びたい方は是非ご検討ください。
アップデートなどの更新事項があれば随時反映しています。(更新履歴)
なお購入後に最新版をダウンロードするには
Amazonへの問い合わせが必要です。