Power Automate Desktop PDFの内容をテキストファイルに保存
PDFファイル内のテキストを抽出してテキストファイルに保存する方法を紹介します。
フロー作成
テキスト情報の場合
まず最初に「PDF からテキストを抽出」を設置し、対象のPDFを指定します。
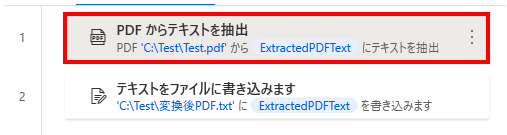

次に「テキストをファイルに書き込みます」を設置すれば完了です。
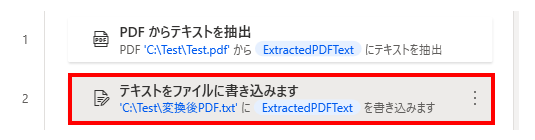
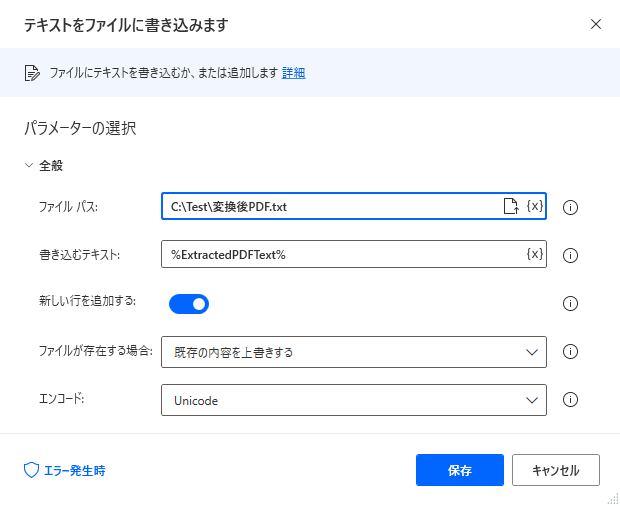
オプションには保存先のテキストファイル、
書き込むテキストに%ExtractedPDFText%を指定します。
(生成された変数の名前を変えていない場合)
画像からテキストを抽出する場合
画像からもある程度、テキストを抽出可能です。
ただしOCRのためうまく読み込めない場合があります。
またテキストと画像は別々に抽出するため
テキスト・画像を通して順番通りにはできません。
(ページ番号でループさせればある程度は可能ですが)
フローを作成するには、まず「PDF から画像を抽出します」を設置します。
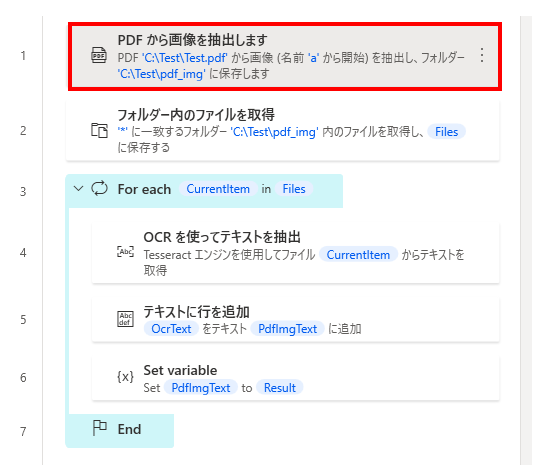
次に「フォルダー内のファイルを取得する」を設置して、
「PDF から画像を抽出します」 の保存先フォルダを指定します。

次にFor eachを設置し、反復を行う値に%Files%を指定します。
(「フォルダー内のファイルを取得する」で生成された変数)
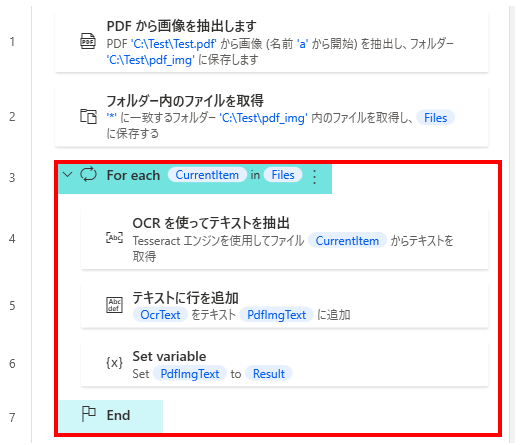
次にFor eachの中に「OCRを使ってテキストを抽出」を設置します。
(日本語で利用する際には事前準備が必要です。詳細はアクションのページで解説しています)
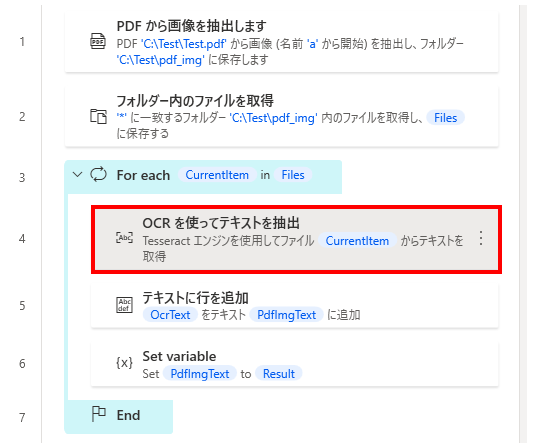
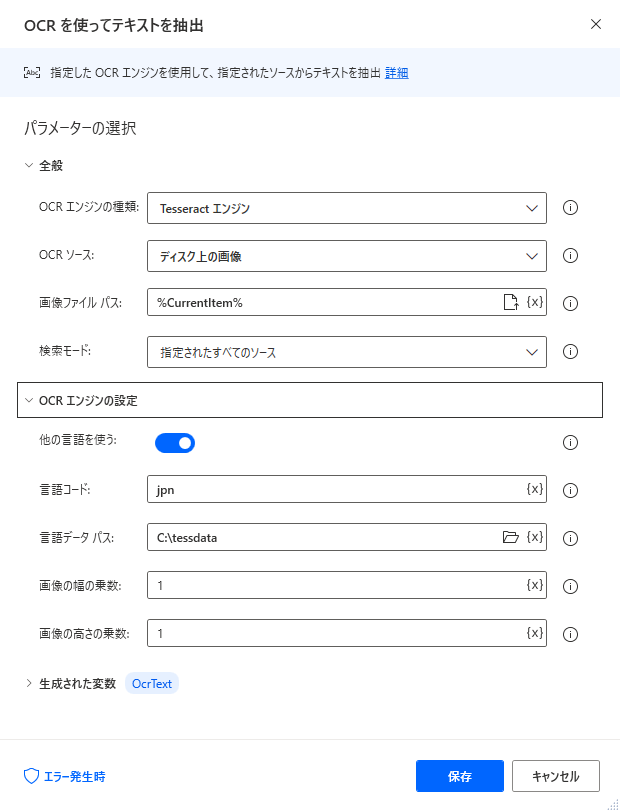
オプションは次のように設定します。
| 項目 | 設定値 | 備考 |
|---|---|---|
| OCRエンジンの種類 | Tesseract エンジン | |
| OCR ソース | ディスク上の画像 | |
| 画像ファイル パス | %CurrentItem% | For eachの生成された変数 |
| 検索モード | 指定されたすべてのソース | |
| 他の言語を使う | ON | |
| 言語コード | jpn | |
| 言語データ パス | jpn.traineddataとjpn_vert.traineddataが 保存されているディレクトリ |
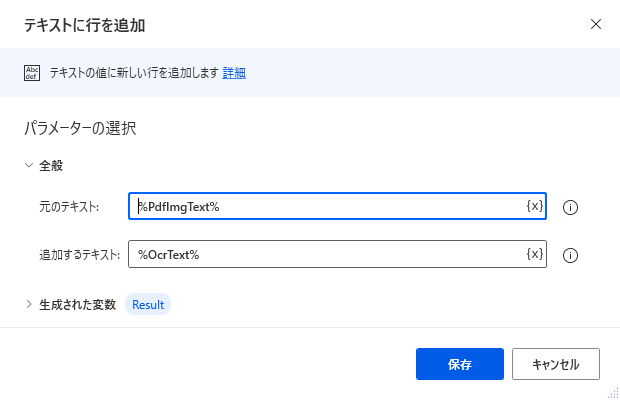
次にFor eachの中に「テキストに行を追加」を設置します。

オプションは次のように設定します。
| 項目 | 設定値 | 備考 |
|---|---|---|
| 元のテキスト | %PdfImgText% | 任意の変数名。 |
| 追加するテキスト | %OcrText% | 「OCRを使ってテキストを抽出」の生成された変数 |

オプションは次のように設定します。
フロー完了後、 %PdfImgText% に対象とした全画像を
OCRで解釈して結合した結果が設定されます。
Power Automate Desktopを「最短」で習得したい方へ
「Webで情報を探す時間がもったいない」と感じていませんか
当サイトの人気記事を体系的に整理し、一冊の電子書籍にまとめました 。

ページをめくるだけで、基礎から応用まで階段を登るようにスキルアップできます。
オフラインでも読めるため、通勤時間や移動中の学習にも最適です。
【本書で学べること】
- 基本操作とフローの作成手順
- Excel、Outlook、Webブラウザの自動化 * 実務で必須のエラー処理と頻出テクニック
Kindle Unlimited会員なら追加料金なし(0円)でお読みいただけます。