Power Automate Desktop「PDF からテキストを抽出」アクション
PDFに含まれているテキスト情報を抽出して変数に格納するアクションです。
画像で表現されている文字の場合は取得できません。
目次
利用方法
「アクション」の「PDF」より「PDF からテキストを抽出」をドラッグします。
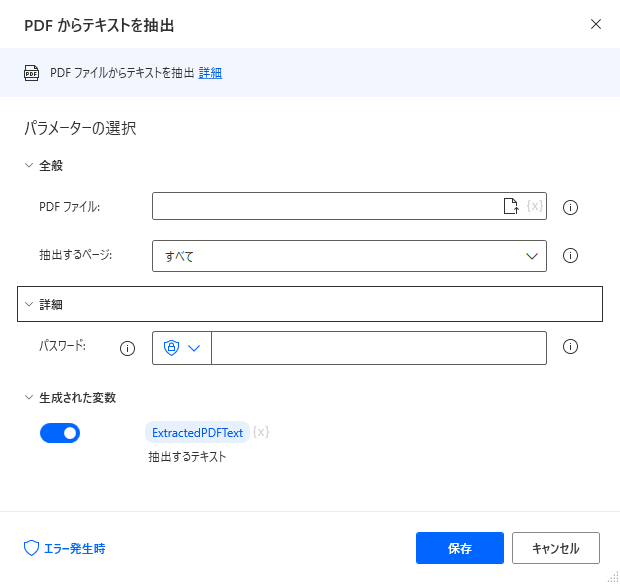
パラメータの設定画面が表示されるので値を指定します。
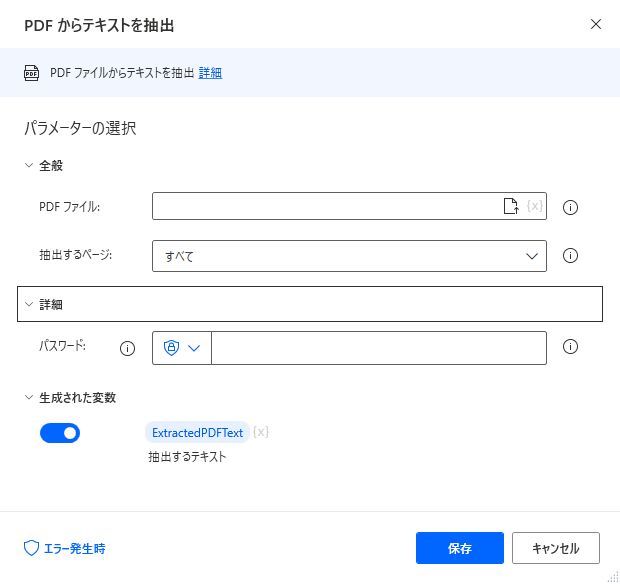
パラメータ
PDF ファイル
抽出対象のPDFファイルを指定します。

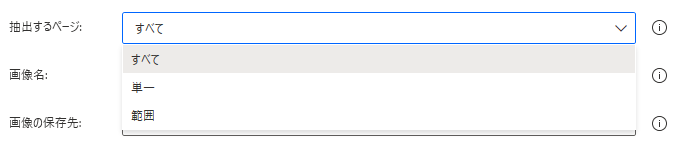
抽出ページ
検索するページを指定します。
単一や範囲の場合、ページ数を追加で指定します。
パスワード
PDFファイルを開くためにパスワードが必要な場合は指定します。

構造化データに最適化
(2022年05月アップデートで追加された項目です)
ONにすると余白をスペースで再現しようとします。
どのように取り込まれるか、ONとOFFでテストしてから決めるとよいでしょう。

生成された変数
ExtractedPDFText
PDFから抽出したテキストが格納されます。

エラー発生時
必須ではありませんが、必要があればエラー処理を行います。
Power Automate Desktopを効率的に習得したい方へ
当サイトの情報を電子書籍用に読み易く整理したコンテンツを
買い切り950円またはKindle Unlimited (読み放題) で提供中です。

Word-A4サイズ:1,700ページの情報量で
(実際のページ数はデバイスで変わります)
基本的な使い方から各アクションの詳細な使い方、
頻出テクニック、実用例を紹介。(目次)
体系的に学びたい方は是非ご検討ください。
アップデートなどの更新事項があれば随時反映しています。(更新履歴)
なお購入後に最新版をダウンロードするには
Amazonへの問い合わせが必要です。