Power Automate Desktop 特定の文字列以前・以降・間の文字を抽出する方法
テキストから指定文字より左または右、間を抽出する方法を紹介します。
手順
指定文字より左・右を抽出
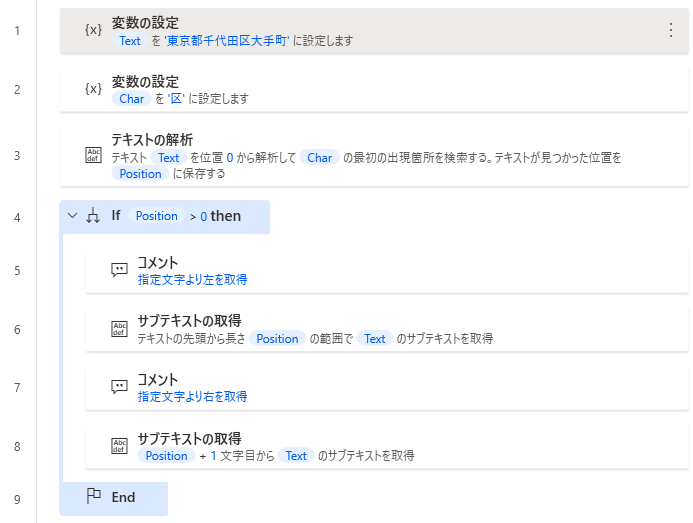
最初に抽出対象のテキスト(%Text%)と文字(%Char%)の変数を用意します。
変数名は任意です。

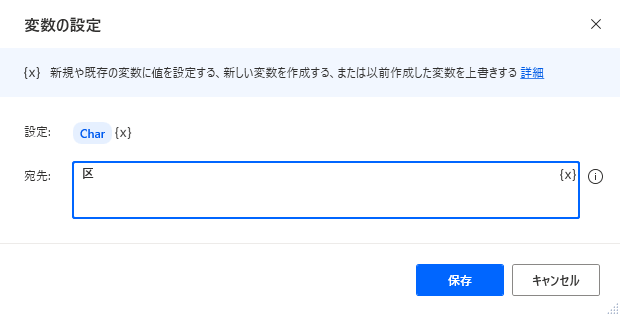
「テキストの解析」で指定文字の位置を検索します。
| 項目 | 設定値 |
|---|---|
| 解析するテキスト | %Text% |
| 検索するテキスト | %Char% |
| 正規表現である | OFF |
| 解析の開始位置 | 0 |
| 最初の出現箇所のみ | ON |
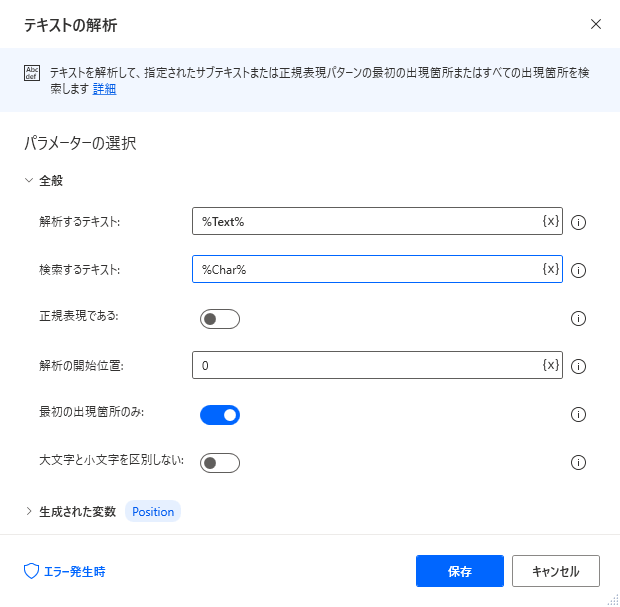
次に「If」を設置してエラーしないように内容チェックします。
| 項目 | 設定値 |
|---|---|
| 最初のオペランド | %Position% |
| 演算子 | より大きい(>) |
| 2番目のオペランド | 0 |

指定文字より左を抽出する場合は次のように設定します。
| 項目 | 設定値 |
|---|---|
| 元のテキスト | %Text% |
| 開始インデックス | テキストの先頭 |
| 長さ | 文字数 |
| 文字数 | %Position% |
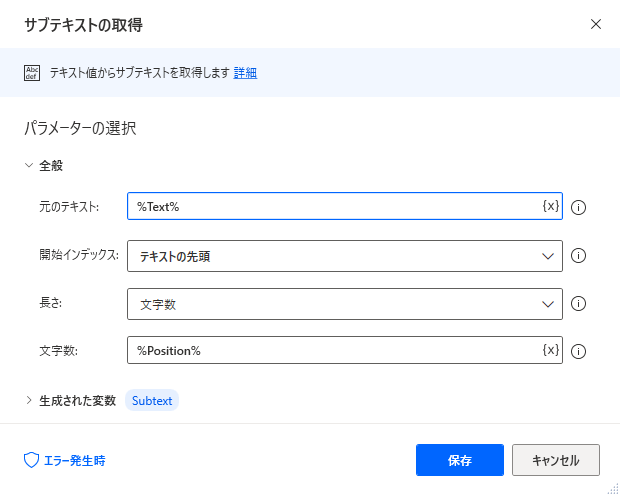
右から残す場合は次のように設定します。
| 項目 | 設定値 |
|---|---|
| 元のテキスト | %Text% |
| 開始インデックス | 文字の位置 |
| 文字の位置 | %Position + 1% |
| 長さ | テキストの末尾 |

フローを実行すると「サブテキストの取得」の生成された変数に
抽出したテキストが設定されます。今回の例では次のようになります。
| 抽出するテキスト | 東京都千代田区大手町 |
| 指定文字 | 区 |
| 左を抽出 | 東京都千代田 |
| 右を抽出 | 大手町 |
指定文字の間を抽出
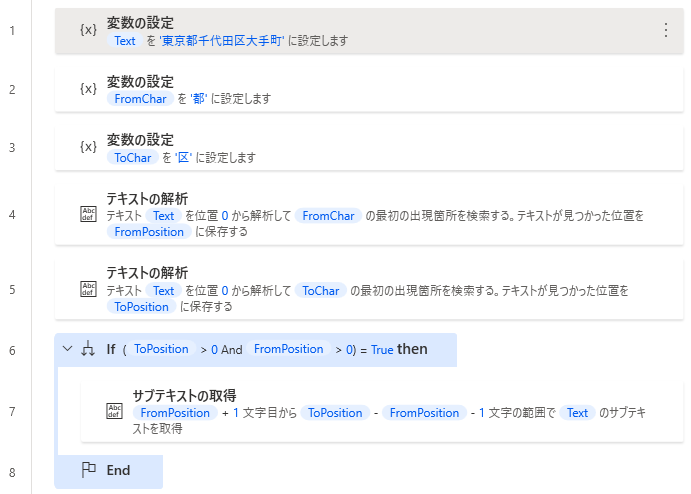
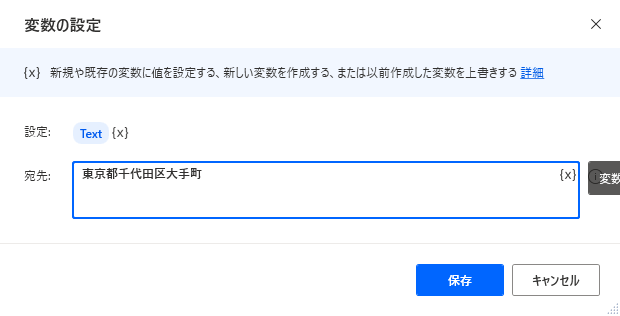
最初に抽出対象のテキスト(%Text%)と
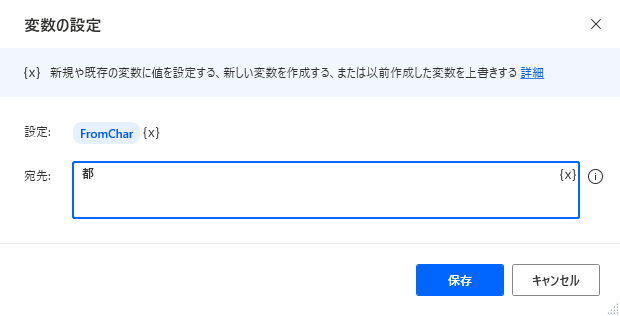
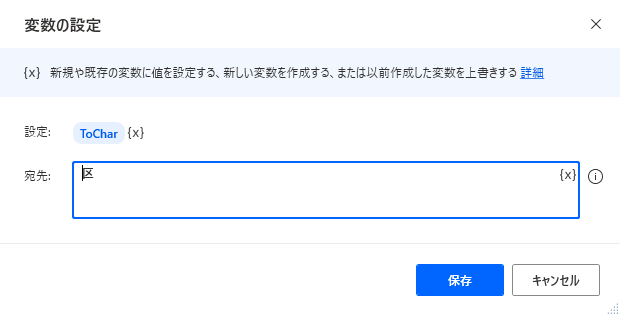
抽出開始文字(%FromChar%)、 抽出終了文字(%ToChar%) の変数を用意します。
変数名は任意です。
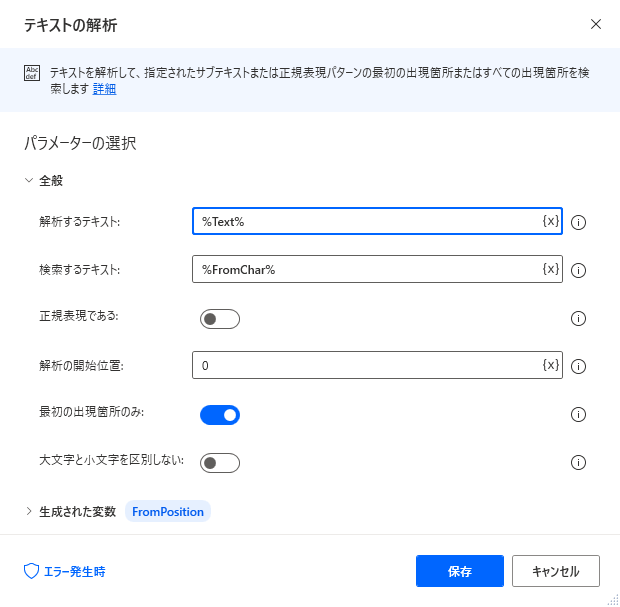
次に「テキストの解析」を二つ設置して開始文字と終了文字の位置を検索します
| 項目 | 設定値 |
|---|---|
| 解析するテキスト | %Text% |
| 検索するテキスト | %FromChar% |
| 正規表現である | OFF |
| 解析の開始位置 | 0 |
| 最初の出現箇所のみ | ON |
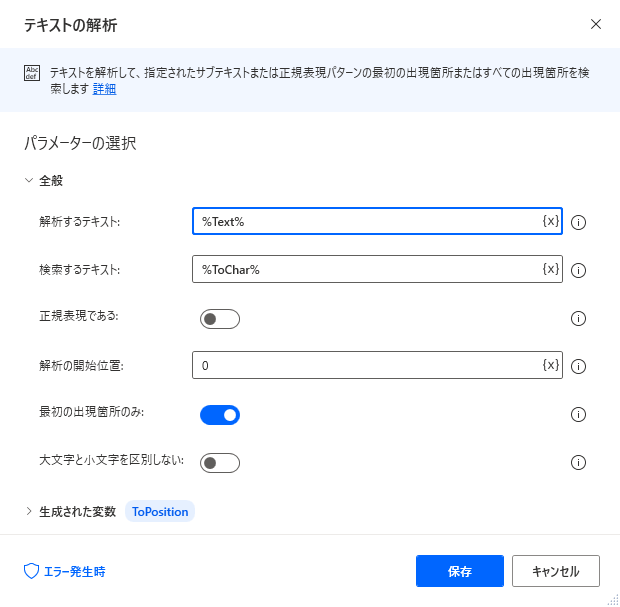
| 項目 | 設定値 |
|---|---|
| 解析するテキスト | %Text% |
| 検索するテキスト | %FromChar% |
| 正規表現である | OFF |
| 解析の開始位置 | 0 |
| 最初の出現箇所のみ | ON |
次に「If」を設置してエラーしないように内容チェックします。
| 項目 | 設定値 |
|---|---|
| 最初のオペランド | %ToPosition > 0 AND FromPosition > 0% |
| 演算子 | と等しい(=) |
| 2番目のオペランド | %True% |

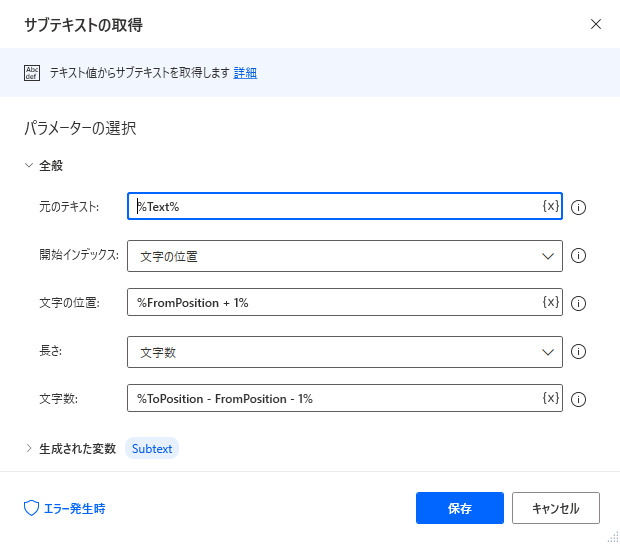
| 項目 | 設定値 |
|---|---|
| 元のテキスト | %Text% |
| 開始インデックス | 文字の位置 |
| 文字の位置 | %FromPosition + 1% |
| 長さ | 文字数 |
| 文字数 | %ToPosition - FromPosition - 1% |
フローを実行すると「サブテキストの取得」の生成された変数に
抽出したテキストが設定されます。今回の例では次のようになります。
| 抽出するテキスト | 東京都千代田区大手町 |
| 抽出開始文字 | 都 |
| 抽出開始文字 | 区 |
| 結果 | 千代田 |
Power Automate Desktopを効率的に習得したい方へ
当サイトの情報を電子書籍用に読み易く整理したコンテンツを
買い切り950円またはKindle Unlimited (読み放題) で提供中です。

Word-A4サイズ:1,700ページの情報量で
(実際のページ数はデバイスで変わります)
基本的な使い方から各アクションの詳細な使い方、
頻出テクニック、実用例を紹介。(目次)
体系的に学びたい方は是非ご検討ください。
アップデートなどの更新事項があれば随時反映しています。(更新履歴)
なお購入後に最新版をダウンロードするには
Amazonへの問い合わせが必要です。