Power Automate Desktop「PDFからテーブルを抽出する」アクション
PDFに含まれている表を抽出してデータテーブルのリストに格納するアクションです。
利用方法
「アクション」の「PDF」より「PDFからテーブルを抽出する」をドラッグします。
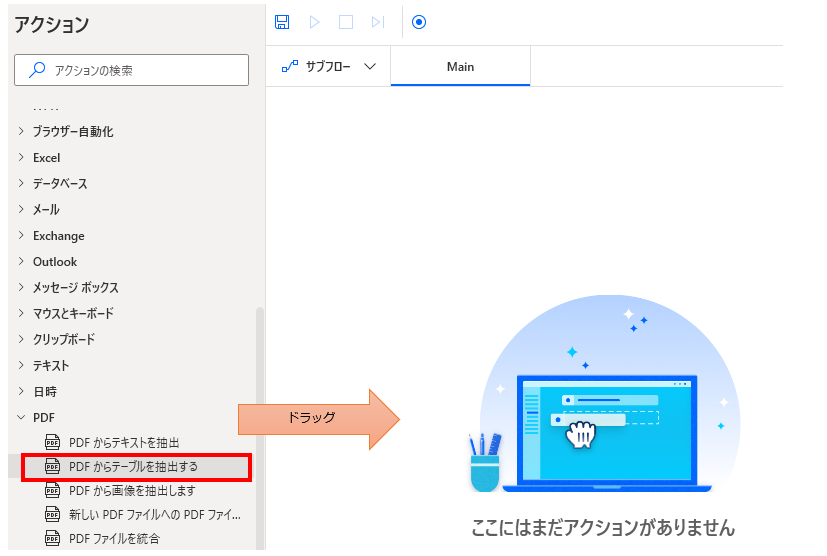
パラメータの設定画面が表示されるので値を指定します。
生成された変数
ExtractedPDFTables
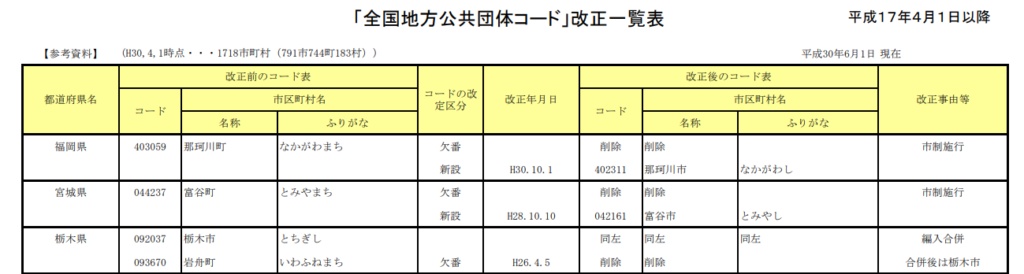
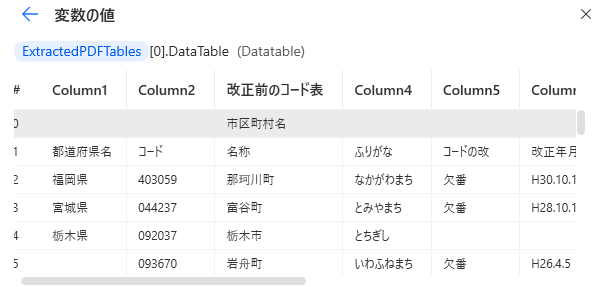
例えば総務省の「都道府県コード及び市区町村コード」のPDFは
大きく二つの表に分かれています。
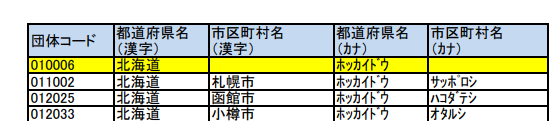

このPDF全体を取り込むと次のようなリストになります。
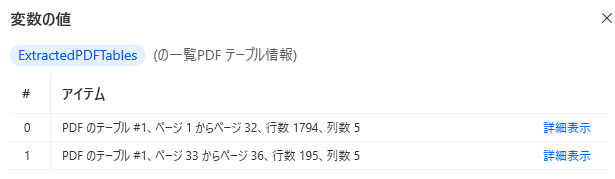
ExtractedPDFTables[0].DataTableが1つ目の表、
ExtractedPDFTables[1].DataTableが2つ目の表のデータテーブルになります。
| プロパティ | |
|---|---|
| .DataTable | データテーブル形式の表本体です。 |
| .TableStartingPage | PDF中の開始ページ位置です。 |
| .TableEndingPage | PDF中の終了ページ位置です。 |


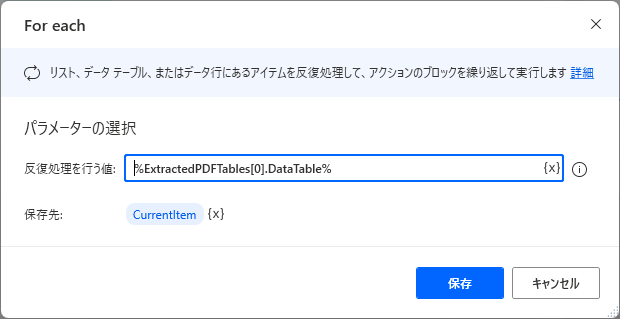
例えば一つ目の表を行ループする場合は、
%ExtractedPDFTables[0].DataTable%を指定します。
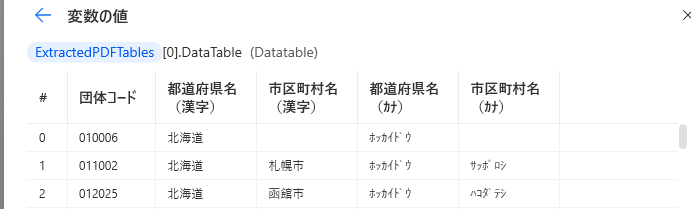
列名を取り込む設定の場合は表の先頭行が列名になります。
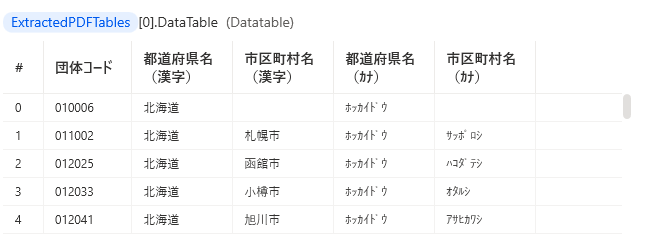
ヘッダが複数行あるPDFの場合は先頭行のみ列名となり、
2行目以降はデータ行になってしまいます。
行ループの中でヘッダーを判定して除外する必要があります。
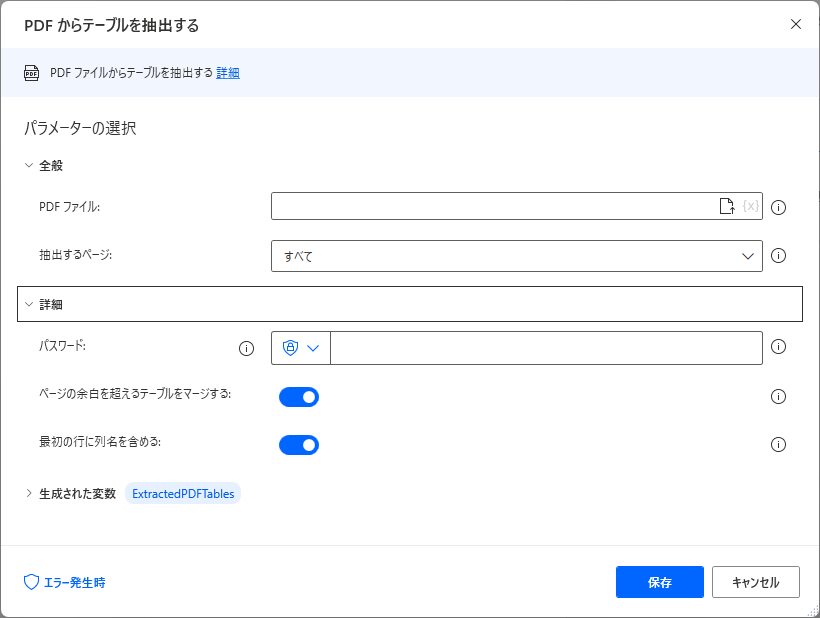
パラメータ
PDF ファイル
抽出対象のPDFファイルを指定します。

表があれば大抵のPDFは取り込めますが
サンプルとして総務省の「都道府県コード及び市区町村コード」のような
列が1行のPDFが取り込みやすいです。

抽出するページ
PDFの中で表を抽出する対象のページを指定します。



パスワード
PDFの読み取りにパスワードが必要な場合に指定します。

ページの余白を超えるテーブルをマージする

表の途中にページ区切りがある場合に、
チェックしていると同じデータテーブルに抽出しますが、
チェックなしの場合、分割して設定します。


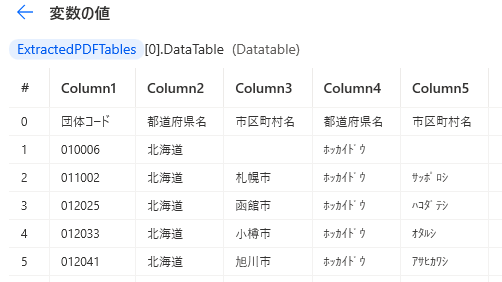
最初の行に列名含める

チェックした場合は先頭行が列名として扱われます。
チェックなしの場合は先頭行もデータ行として扱い、
Column1~が列名として自動設定されます。
Power Automate Desktopを効率的に習得したい方へ
当サイトの情報を電子書籍用に読み易く整理したコンテンツを
買い切り950円またはKindle Unlimited (読み放題) で提供中です。

Word-A4サイズ:1,700ページの情報量で
(実際のページ数はデバイスで変わります)
基本的な使い方から各アクションの詳細な使い方、
頻出テクニック、実用例を紹介。(目次)
体系的に学びたい方は是非ご検討ください。
アップデートなどの更新事項があれば随時反映しています。(更新履歴)
なお購入後に最新版をダウンロードするには
Amazonへの問い合わせが必要です。