Power Automate Desktop「Web ページからデータを抽出する」アクション
Webページの表からデータを取得するアクションです。
取得したデータの形式はデータテーブルかExcelになります。
このアクションは以下のアクションで自動化のために起動したブラウザーを対象とします。
利用方法
まず最初に取得対象の表が存在するページを開いておきます。
そして「アクション」の「ブラウザー自動化」、「Web データ抽出」より、
「Web ページからデータを抽出する」を起動アクションより下にドラッグします。
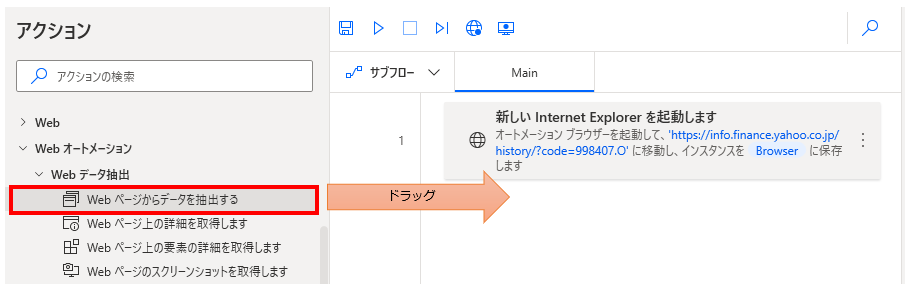
パラメータの設定画面が表示されるので値を指定します。
事前に開いておいた、抽出したい表のあるページを選択します。
すると次のようなウインドウが表示されます。
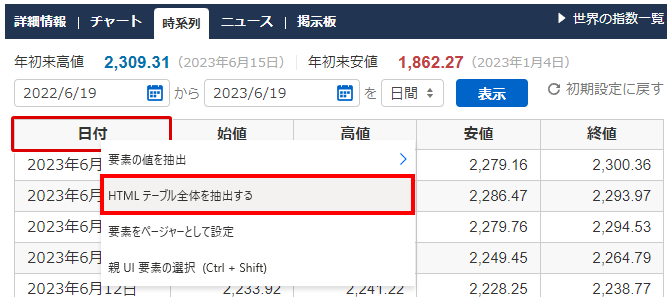
この状態でデータ取得したい表を右クリックしてメニューから
「HTMLテーブル全体を抽出する」を選択します。
ページ切り替えがある場合は次ページに移動するリンクやボタンを右クリックし、メニューから「要素をページャーとして設定」を選択します。
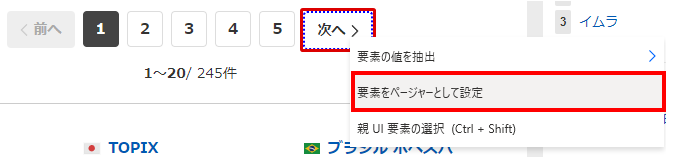
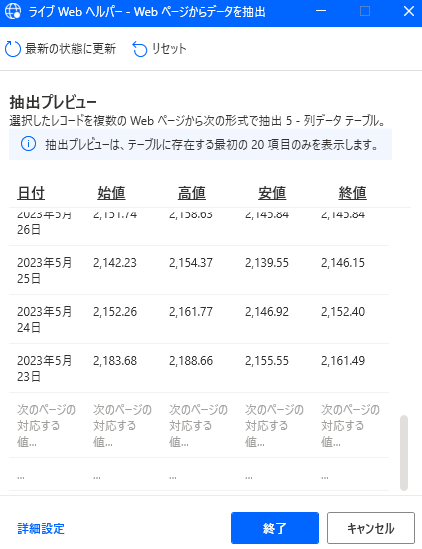
設定に成功すると表の内容が表示され、データの末尾に「次のページに対応する値…」が表示されます。
この状態で「終了」をクリックします。
パラメータ
Web ブラウザー インスタンス
対象のブラウザー(起動アクションで生成された変数)を指定します。
このアクションの実行時点で指定ブラウザーに取得対象の表が表示されている必要があります。

データの抽出元
ページャーを設定している場合、どこまで抽出するかを指定します。

最初のみ
最大ページ数を指定します。0と1では最初のページのみです。

すべて使用できます
すべてのページから取得します。

抽出時にデータを処理する
2022年3月アップデートで追加された項目です。
基本的に動作の軽いOFFのままで構いません。

フィルタリング機能のあるテーブルで
フィルター結果も反映したい場合にONにします。
参考サイト:HTMLのtableをExeclのようにフィルタする(CMANインターネットサービス様)
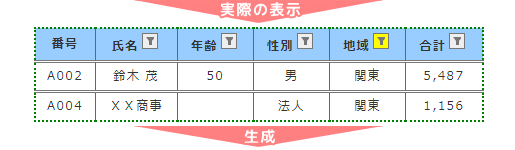
OFFの場合はフィルターがかかっていてもなくても全データを取得します。
ONの場合はフィルターされているデータを取得しません。
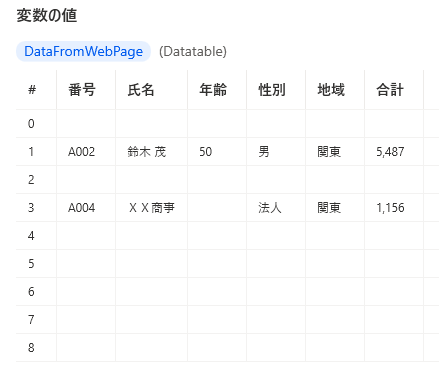
例えば「地域」を「関東」のみにします。
タイムアウト
2022年3月アップデートで追加された項目です。
タイムアウトまでの秒数を指定します。
この秒数まで抽出が完了しなければエラーになります。
通常は変更の必要がありませんが、大きい表からデータ取得する場合にタイムアウトの値を大きくする必要があります。

データ保存モード
データの取得結果の形式を指定します。
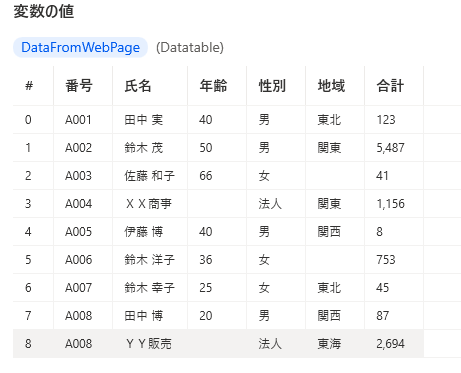
変数
データテーブル(変数名DataFromWebPage)で結果を取得します。

Excelスプレッドシート
Excelで結果(変数名ExcelInstance)を取得します。
Excelを閉じるを使用してファイルとして保存するケースが多いでしょう。

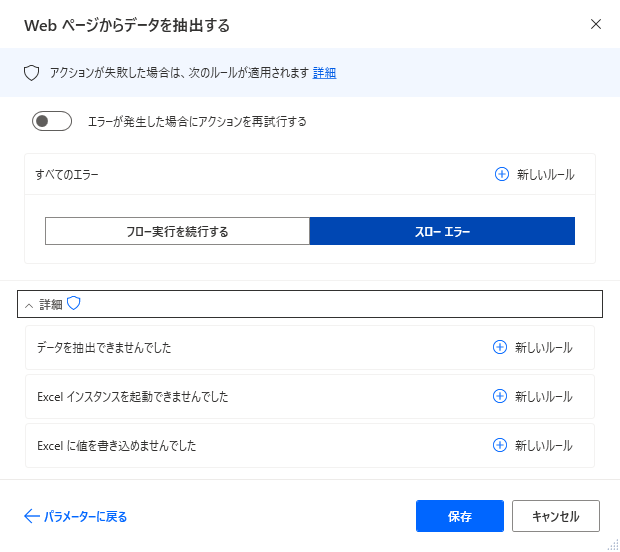
エラー発生時
必須ではありませんが、必要があればエラー処理を行います。
Power Automate Desktopを効率的に習得したい方へ
当サイトの情報を電子書籍用に読み易く整理したコンテンツを
買い切り950円またはKindle Unlimited (読み放題) で提供中です。

Word-A4サイズ:1,700ページの情報量で
(実際のページ数はデバイスで変わります)
基本的な使い方から各アクションの詳細な使い方、
頻出テクニック、実用例を紹介。(目次)
体系的に学びたい方は是非ご検討ください。
アップデートなどの更新事項があれば随時反映しています。(更新履歴)
なお購入後に最新版をダウンロードするには
Amazonへの問い合わせが必要です。