Power Automate CSVファイルを読み込む方法
この記事では有料外部サービスなどを利用せず標準のアクションのみでCSVファイルを
PowerAutomateに読み込み1セルずつ利用する方法を紹介します。
共通手順
可能な限り1見出し1アクション、フローの順番で記載していきます。
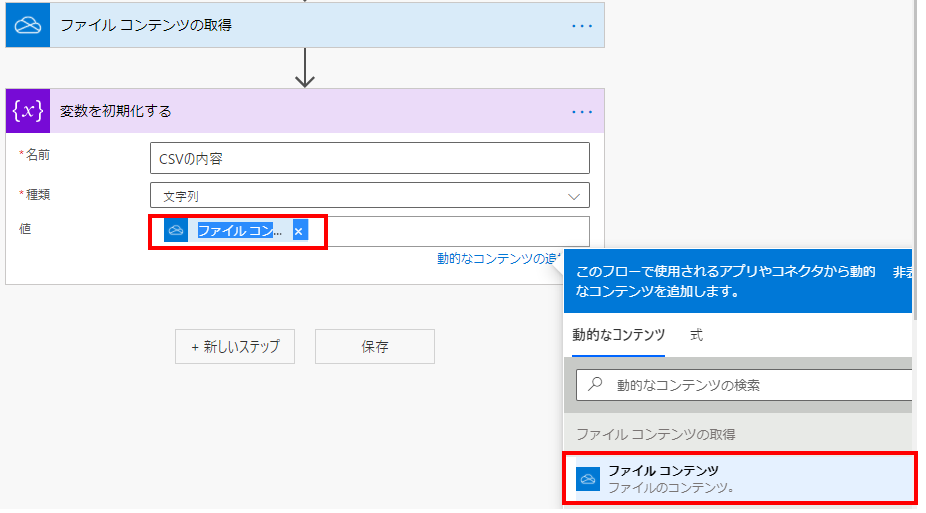
CSVの内容を変数に格納
まず何らかの方法でCSVファイルをファイルコンテンツの形で取得する必要があります。
| アクション・トリガー | 種類 | 動的なコンテンツ |
|---|---|---|
| 新しいメールが届いたとき(Offce365 Outlook) | トリガー | 添付ファイル コンテンツ |
| 新しいメールが届いたとき(Gmail) | トリガー | 添付ファイル コンテンツ |
| ファイルが作成されたとき(OneDrive For Business) | トリガー | ファイル コンテンツ |
| ファイルが変更されたとき(OneDrive For Busiess) | トリガー | ファイル コンテンツ |
| ファイル コンテンツの取得(OneDrive For Business) | アクション | ファイル コンテンツ |
| パスによるファイル メタデータの取得(OneDrive For Business) | アクション | ファイル コンテンツ |
| ファイルの変換(OneDrive For Business) | アクション | ファイル コンテンツ |
| IDによるファイルコンテンツの取得(GoogleDrive) | アクション | ファイル コンテンツ |
| パスによるファイルコンテンツの取得(GoogleDrive) | アクション | ファイル コンテンツ |
| フォルダー内にファイルが作成されたとき(SharePoint) | トリガー | ファイル コンテンツ |
| フォルダー内でファイルが作成または変更されたとき(SharePoint) | トリガー | ファイル コンテンツ |
OneDriveやGoogleDriveなどサービスを跨いでも
ダウンロード可能なファイルであれば共通して利用可能です。
基本的にはOneDriveやGoogleDriveにファイルを置くか、
メールの添付ファイルとして受け取ったCSVを処理します。
そして必須ではありませんが、扱いやすくするために
ファイルコンテンツを文字列型の変数に格納します。
改行を変数に格納
更に改行の変数を作ります。

単純なCSVの場合
”(ダブルコーテーション)なしで、
,(カンマ)と改行が列行の区切り以外に発生しないシンプルなCSVの場合です。
(発生する場合はいっそTSVにファイル形式を変えたい所ではありますが…)
コード,名称,価格 A-001,まぐろ,500 A-002,さば,300 A-003,さんま,200
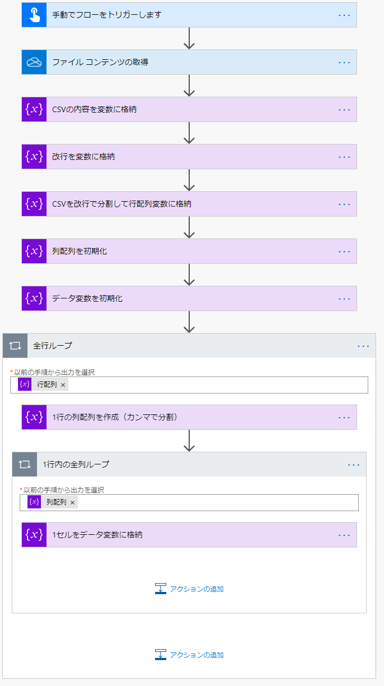
フローの全体像は以下のようになります。
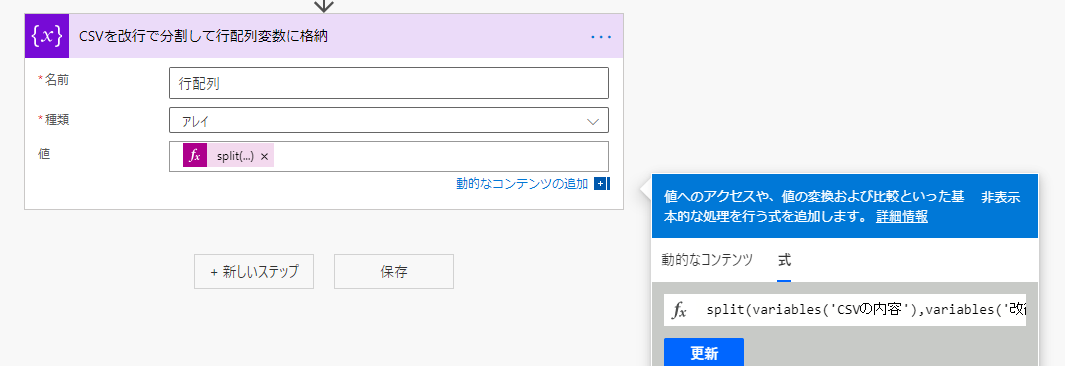
CSVを改行で分割して行配列変数に格納
以下の式で行毎に分割してアレイ(配列)変数に格納します。
split(variables('CSVの内容'),variables('改行'))
今回のサンプルでは以下のような状態のアレイ(配列)になります。
| インデックス | 内容 |
|---|---|
| 0 | コード,名称,価格 |
| 1 | A-001,まぐろ,500 |
| 2 | A-002,さば,300 |
| 3 | A-003,さんま,200 |
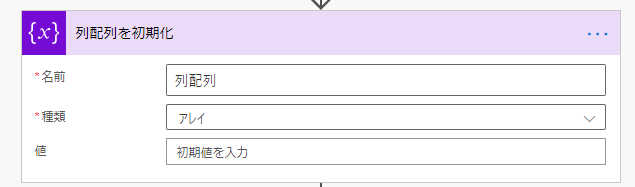
列配列を初期化
のちのアクションで利用するアレイ(配列)変数を初期化しておきます。
初期値は不要です。
データ変数を初期化
のちのアクションで利用する文字列変数を初期化しておきます。
初期値は不要です。
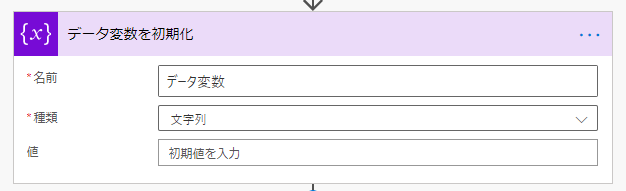
全行ループ
「Apply to each」の「以下の手順から出力を選択」に行配列変数を指定します。
こうすると全行に対してアクションを実行します。
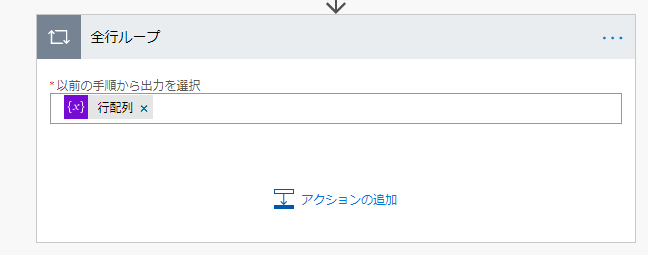
1行の列配列を作成(カンマで分割)
全行ループの中で以下の式を実行し列配列変数に格納します。
split(items('全行ループ'),',')
今回の例では列配列変数は以下のような状態になります。
| インデックス | 内容 |
|---|---|
| 0 | コード |
| 1 | 名称 |
| 2 | 価格 |
| インデックス | 内容 |
|---|---|
| 0 | A-001 |
| 1 | まぐろ |
| 2 | 500 |
| インデックス | 内容 |
|---|---|
| 0 | A-002 |
| 1 | さば |
| 2 | 300 |
| インデックス | 内容 |
|---|---|
| 0 | A-003 |
| 1 | さんま |
| 2 | 200 |
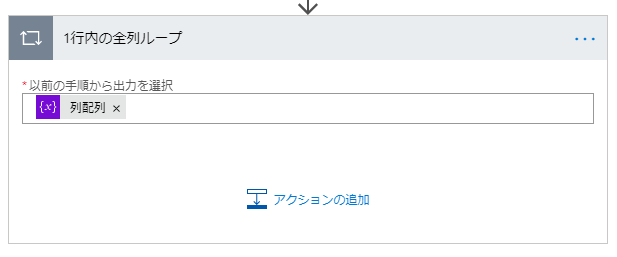
1行内の全列ループ
「Apply to each」の「以下の手順から出力を選択」に列配列変数を指定します。
こうすると1行内の全列に対してアクションを実行します。
1セルをデータ変数に格納
1行内の全列ループの現在のアイテムをデータ変数に格納します。
(動的なコンテンツのまま使用してもかまいません)
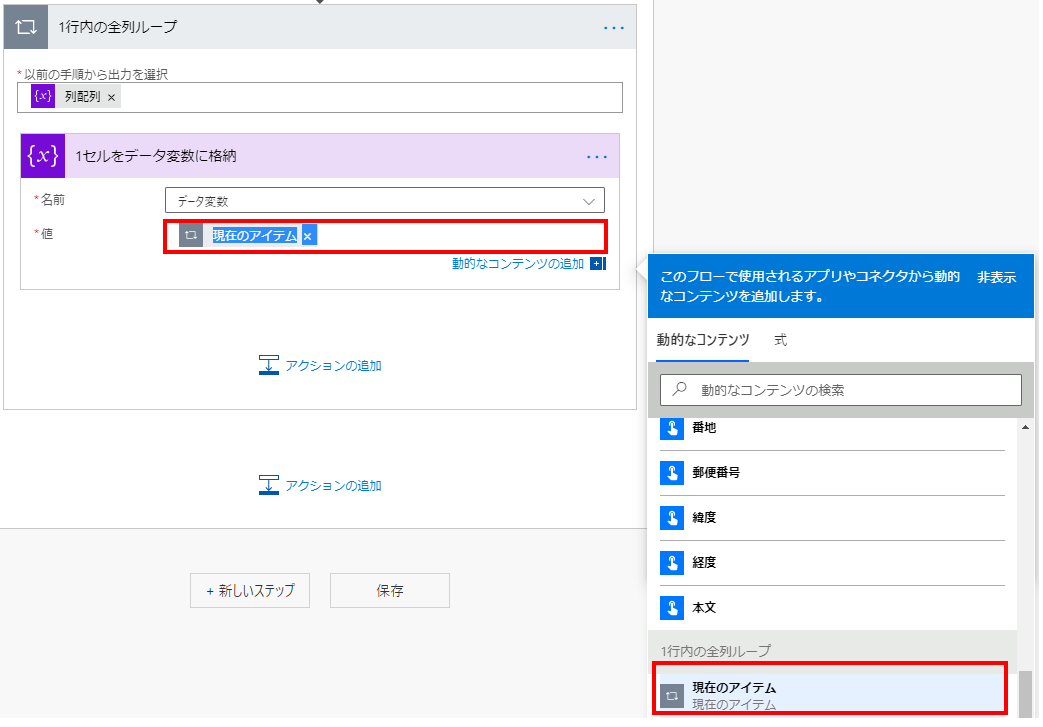
これによりCSVの内容を1セルずつ利用可能です。
複雑なCSVの場合
一般に利用される以下の仕様を読み込みます。
- 項目を"(ダブルコーテーション)で囲む
- 項目内に,(カンマ)が発生する
- 項目内に"が発生する場合は、二重で""とする
"コード","名称","価格" "A-001","まぐ""ろ","5,000" "A-002","さ""ば","3,000" "A-003","さん""ま","2,000"
PowerAutomateの仕様と激戦でかなり複雑なフローになっています。
エクスポートしようかと思ったのですが、
入ってほしくない情報がかなり入っているので諦めました。
代わりにテンプレートに申請してみましたが、どうなるやら。
(承認されるなら記載します)
概要としてはCSVをJSON形式の二次元配列に変換して変数に取り込みます。
先述のサンプルではこのようなJSONに変換します。(""は\"になりますが、扱いは”です)
{
"行配列": [
[
"コード",
"名称",
"価格"
],
[
"A-001",
"まぐ\"ろ",
"5,000"
],
[
"A-002",
"さ\"ば",
"3,000"
],
[
"A-003",
"さん\"ま",
"2,000"
]
]
}取り込んだCSVは「取り込み後CSV配列」変数からアクセスします。
そのフローの全体像は以下のようになります。
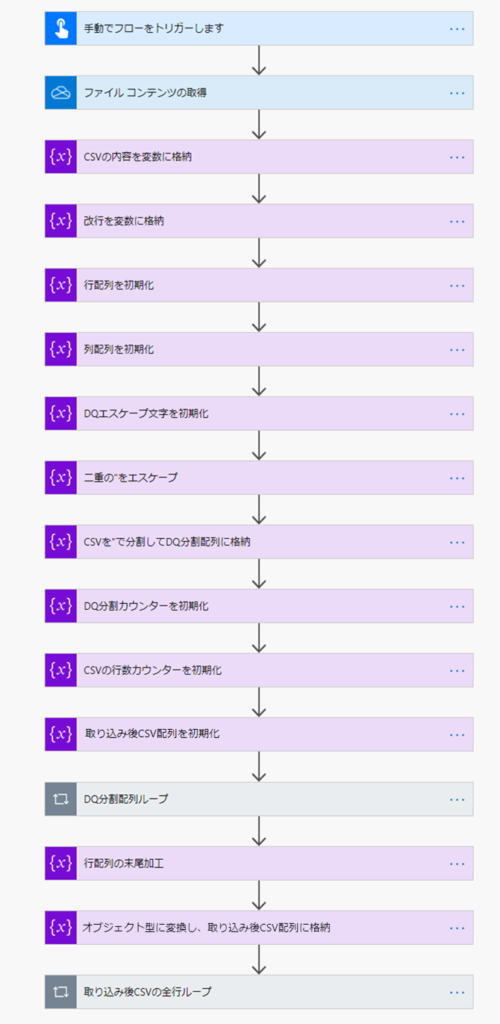
ループの中に色々あります。(テンプレート承認されてほしい…)
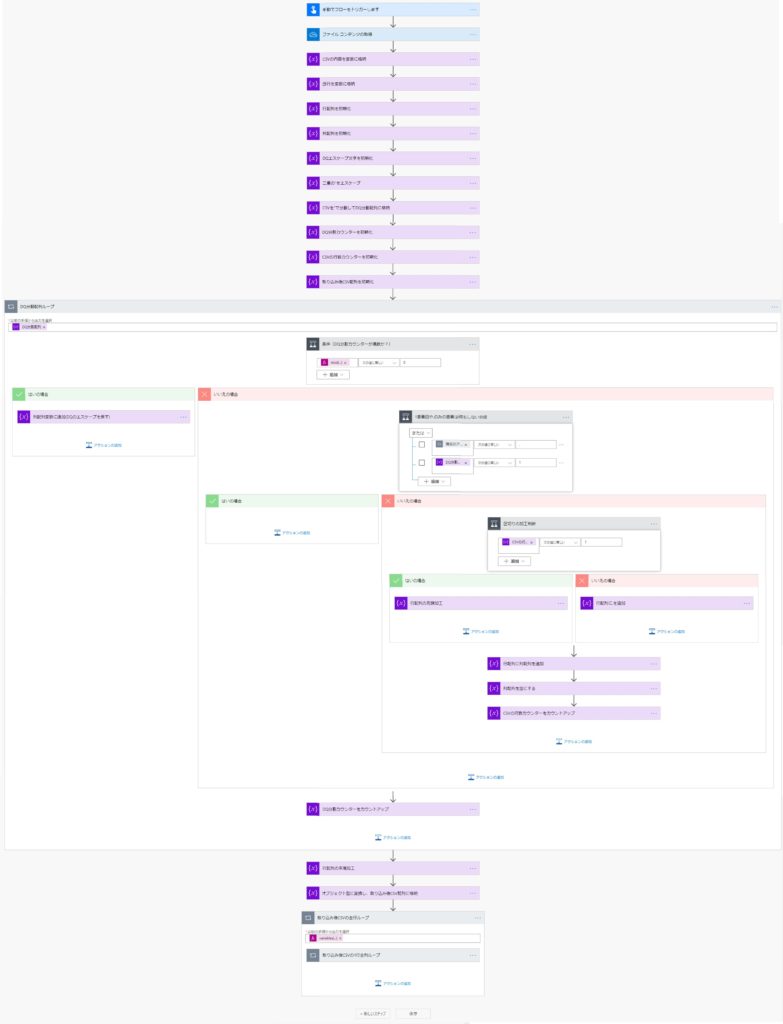
作成にあたって最初のトリガーとCSVのファイルコンテンツの取得は任意のもので設定してください。
(ステップ名や変数名も任意ですが、コピペしたほうが楽です)
変数宣言
3番目「CSVの内容を変数に格納」~12番目「取り込み後CSV配列を初期化」は変数宣言です。
全て「変数の初期化」で以下のように設定します。
| ステップ名 | 変数名 | 種類 | 値 | 備考 |
|---|---|---|---|---|
| CSVの内容を変数に格納 | CSVの内容 | 文字列 | CSVのファイルコンテンツ | |
| 改行を変数に格納 | 改行 | 文字列 | 改行 | こちらも参照 |
| 行配列を初期化 | 行配列 | 文字列 | ややこしいですがアレイではありません。文字列(JSONで配列を格納)です。 | |
| 列配列を初期化 | 列配列 | アレイ | ||
| DQエスケープ文字を初期化 | DQエスケープ文字 | 文字列 | =||=DQ=||= | ""を一時的に置換しておく文字列です。CSVに出てこない文字列であれば何でも構いません。 |
| 二重の"をエスケープ | CSVの内容_DQエスケープ後 | 文字列 | replace(variables('CSVの内容'),'""',variables('DQエスケープ文字')) | 値は式で指定します。 ""を一時的に別の文字列に置換します。 |
| CSVを"で分割してDQ分割配列に格納 | DQ分割配列 | アレイ | split(variables('CSVの内容_DQエスケープ後'),'"') | 値は式で指定します。 |
| DQ分割カウンターを初期化 | DQ分割カウンター | 整数 | 0 | |
| CSVの行数カウンターを初期化 | CSVの行数カウンター | 整数 | 0 | |
| 取り込み後CSV配列を初期化 | 取り込み後CSV配列 | オブジェクト | CSVの読み込み結果を格納します。 |
DQ分割配列ループ
「取り込み後CSV配列CSV配列を初期化」の次に「Apply to each」を設置し、
「以下の手順から出力を選択」に「DQ分割配列」変数を指定します。
ステップ名は「DQ分割配列ループ」とし、その中には以下のように設置します。
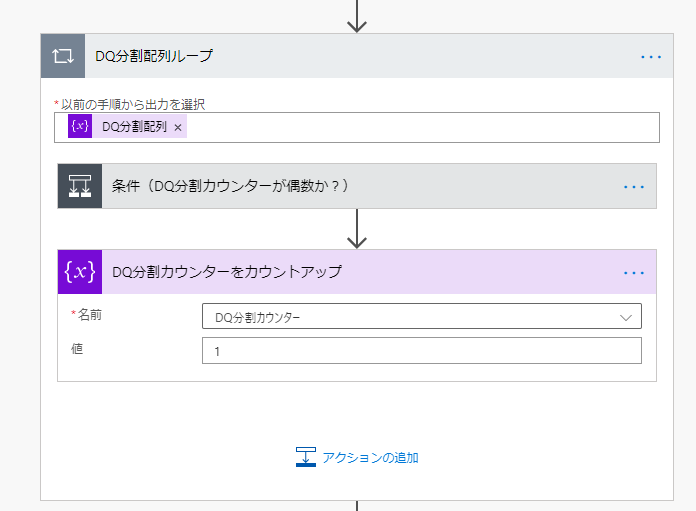
条件(DQ分割カウンターが偶数か?)
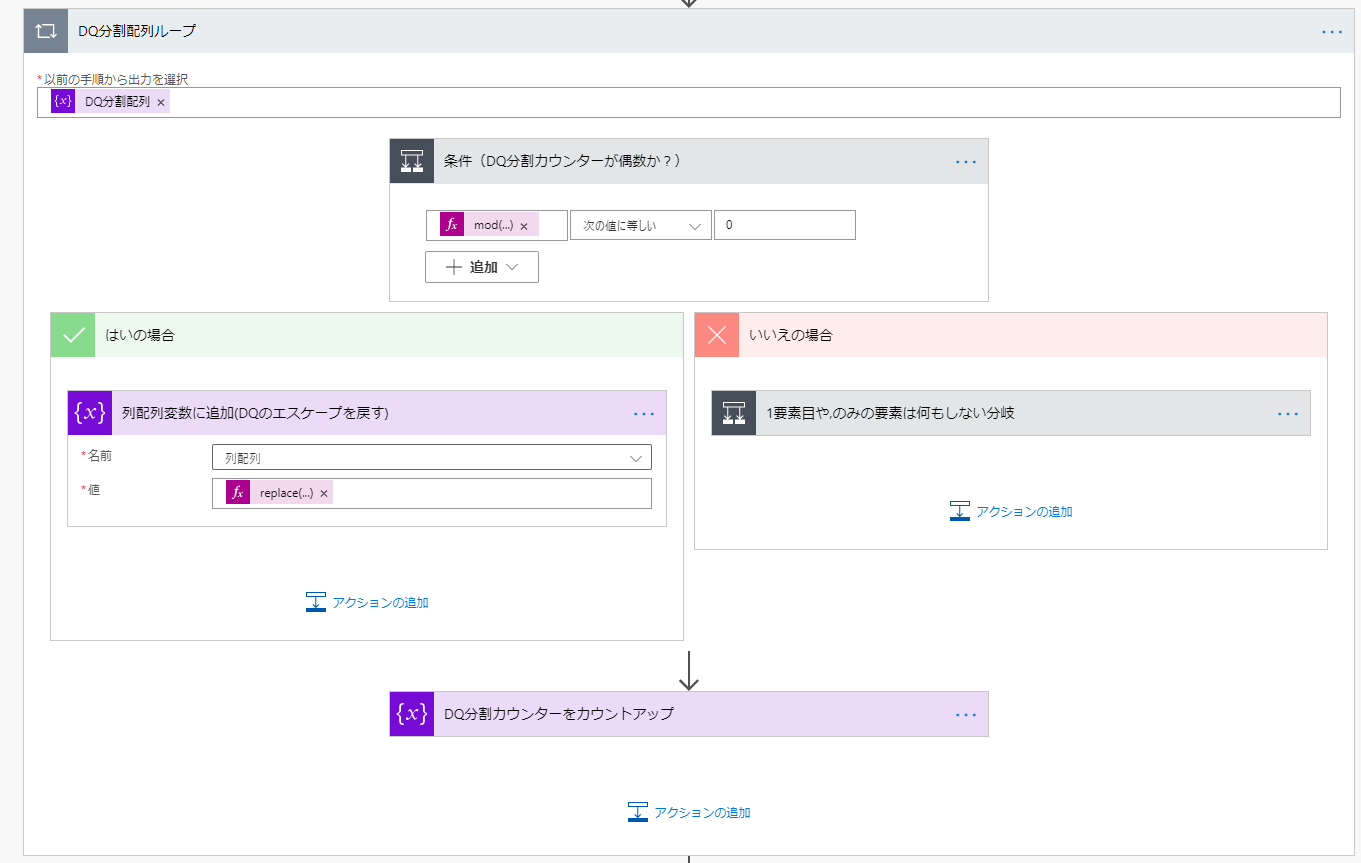
条件(DQ分割カウンターが偶数か?)を以下のように設定します。
左側は式を指定します。mod関数は最初の値を二番目の値で割った余りを出す関数です。
2で割った結果が1余りであれば奇数、0余りであれば偶数と判定できます。
| 左 | 中央 | 右 |
|---|---|---|
| mod(variables('DQ分割カウンター'),2) | 次の値に等しい | 0 |
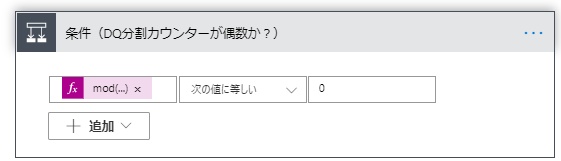
はいの場合は以下のように設置します。
| 設置アクション | ステップ名 | 設定値 | 説明 |
|---|---|---|---|
| 変数の設定 | 列配列変数に追加(DQのエスケープを戻す) | 名前:列配列 値:replace(items('DQ分割配列ループ'),variables('DQエスケープ文字'),'"') | 値は式で指定します。 ""のエスケープを"に変換します。 |
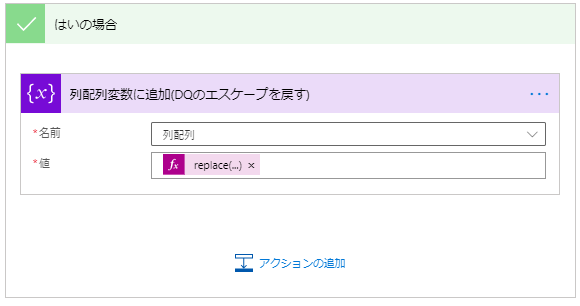
いいえの場合は以下のように設置します。
| 設置アクション | ステップ名 | 設定値 | 説明 |
|---|---|---|---|
| 条件 | 1要素目や,のみの要素は何もしない分岐 | 後述 | 後述 |
1要素目や,のみの要素は何もしない分岐
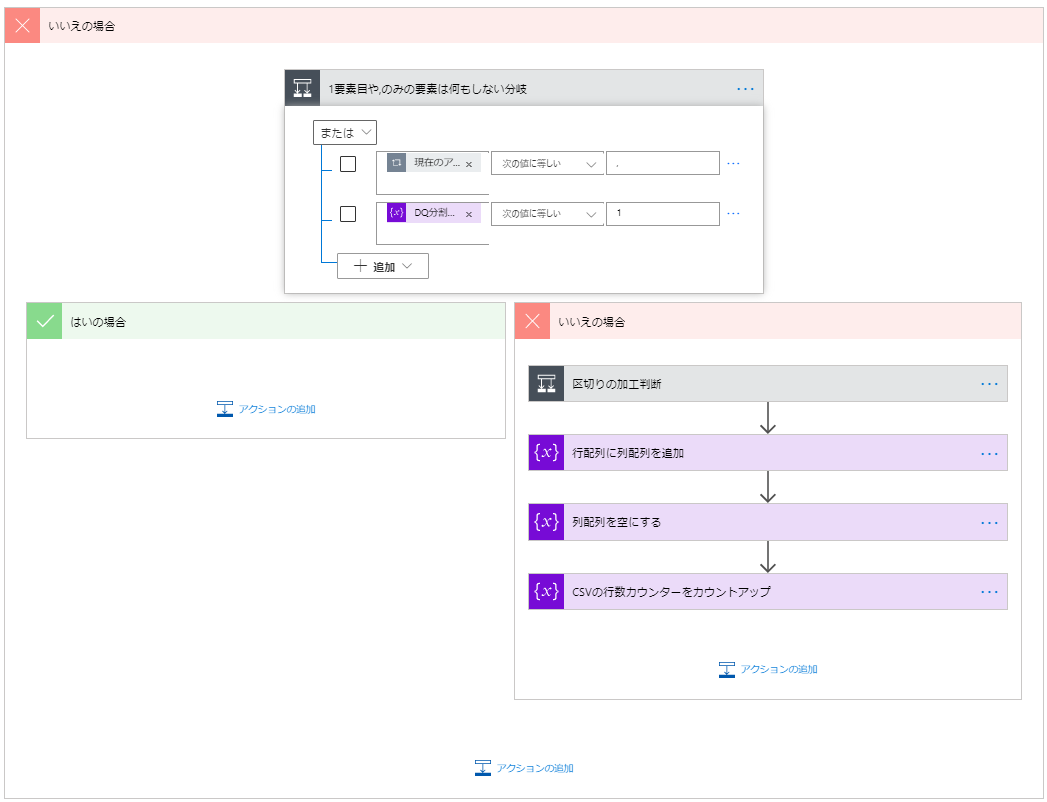
1要素目や,のみの要素は何もしない分岐を以下のように設定します。
「または」で2条件を設定します。
| 左 | 中央 | 右 |
|---|---|---|
| 「DQ分割配列ループ」の現在のアイテム | 次の値に等しい | 0 |
| DQ分割カウンター | 次の値に等しい | 1 |
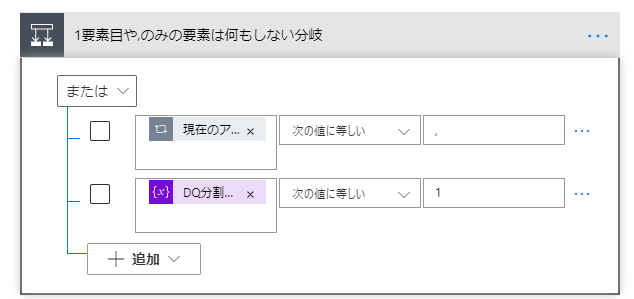
はいの場合には何もしません。いいえの場合は、改行が来ている時です。
| 設置アクション | ステップ名 | 設定値 | 説明 |
|---|---|---|---|
| 条件 | 区切りの加工判断 | 後述 | 後述 |
| 文字列変数に追加 | 行配列に列配列を追加 | 名前:行配列 値:列配列 | |
| 変数の設定 | 列配列を空にする | 名前:列配列 値:[] | |
| 変数の値を増やす | CSVの行数カウンターをカウントアップ | 名前:CSVの行数カウンター 値:1 |
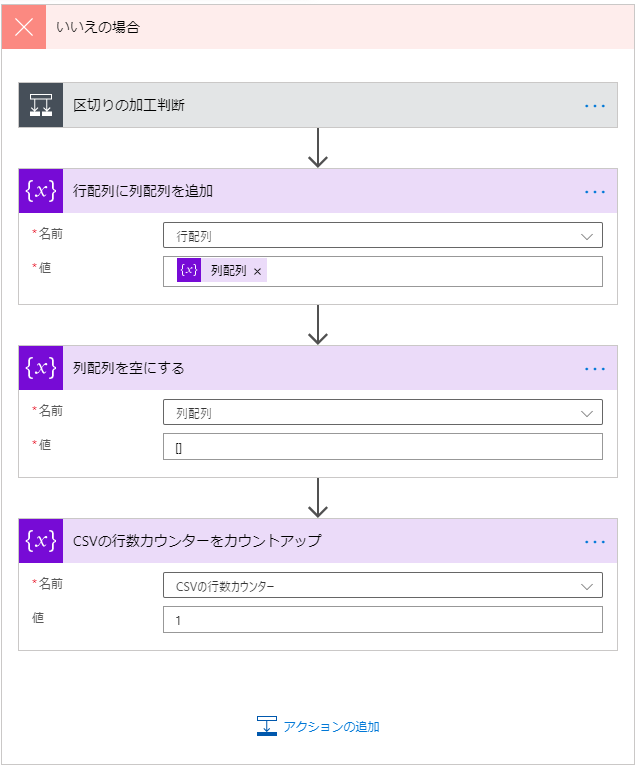
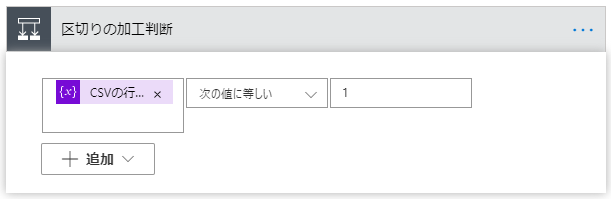
区切りの加工判断
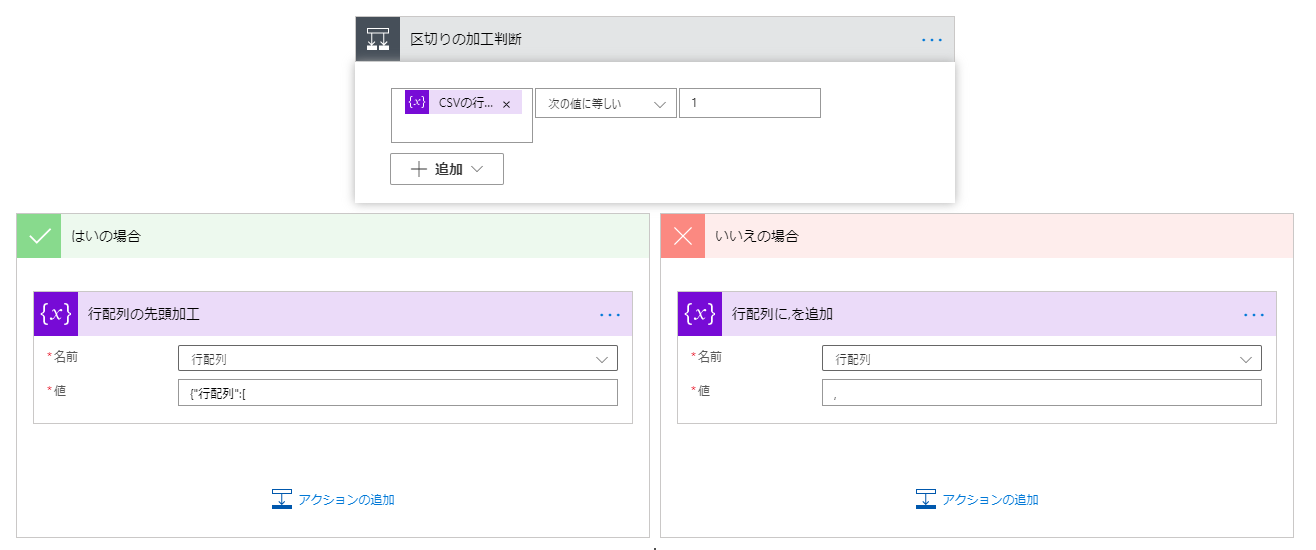
区切りの加工判断を以下のように設定します。
先頭行の場合、JSON部分の先頭部分を作り、
先頭以降の場合、,を追加します。(CSVでなくJSONの区切りです)
| 左 | 中央 | 右 |
|---|---|---|
| CSVの行数カウンター | 次の値に等しい | 1 |
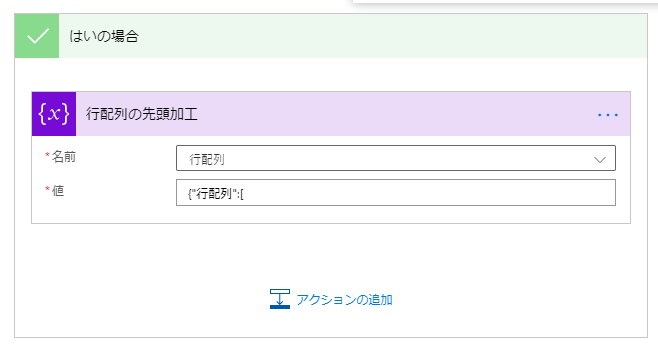
はいの場合は以下のように設置します。
| 設置アクション | ステップ名 | 設定値 | 説明 |
|---|---|---|---|
| 変数の設定 | 行配列の先頭加工 | 名前:行配列 値:{"行配列":[ | 値は式で指定します。 |
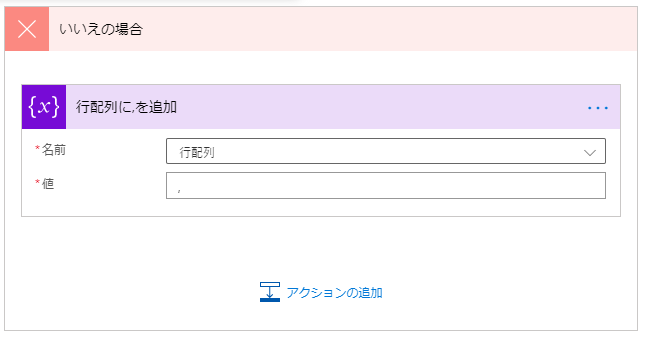
いいえの場合は以下のように設置します。
| 設置アクション | ステップ名 | 設定値 | 説明 |
|---|---|---|---|
| 文字列変数に追加 | 行配列に,を追加 | 名前:行配列 値:, |
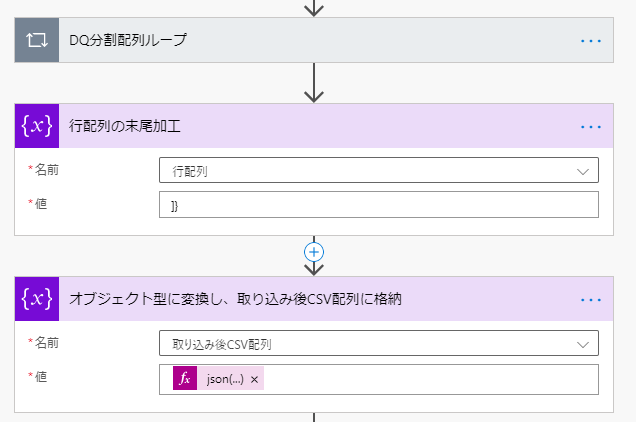
最後の加工
「DQ分割配列ループ」に二つのアクションを設置します。
| 設置アクション | ステップ名 | 設定値 | 説明 |
|---|---|---|---|
| 文字列変数に追加 | 行配列の末尾加工 | 名前:行配列 値:]} | |
| 変数の設定 | オブジェクト型に変換し、取り込み後CSV配列に格納 | 名前:取り込み後CSV配列 値:json(variables('行配列')) | 値は式で指定します。 |
これで読み込み自体は完了です。
加工後CSV配列に行と項目で分割された状態で格納されます。
読み込んだ値の取得
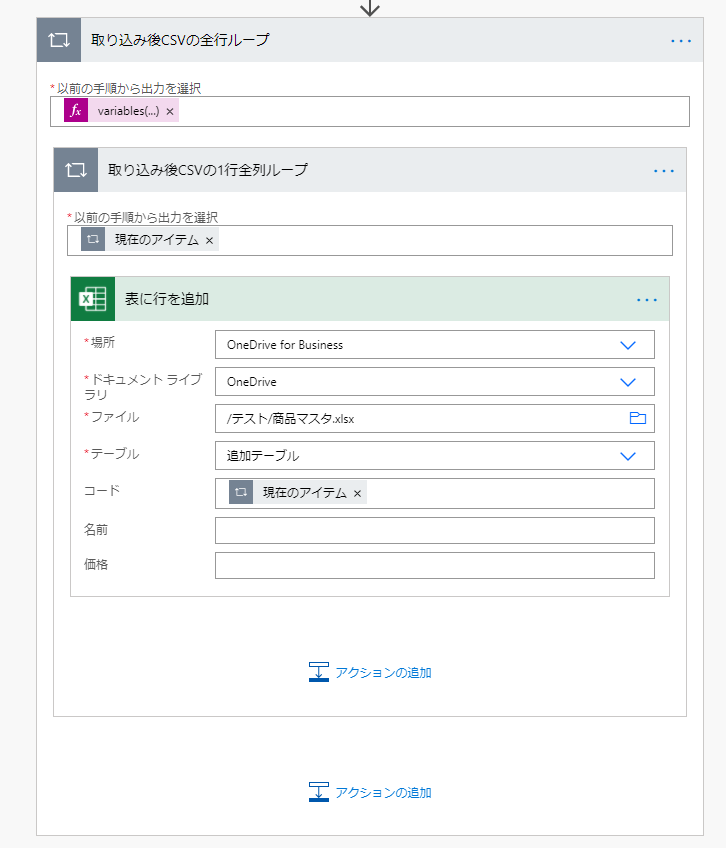
読み込んだCSVの内容は二重の「Apply to each」で利用します。
一つ目の「取り込み後CSVの全行ループ」ではCSVの行数だけ繰り返します。
「以前の手順から出力の選択」には以下の式を指定します。
variables('取り込み後CSV配列').行配列
二つ目の「取り込み後CSVの1行全列ループ」ではCSVの列数だけ繰り返します。
「以前の手順から出力の選択」には「取り込み後CSVの全行ループ」の「現在のアイテム」を指定します。
その中で「取り込み後CSVの1行全列ループ」の「現在のアイテム」を指定すると
CSVの1項目(Excelでいうセル)を取得します。
下の例ではCSVの1項目1行でExcelに追記されます。
Power Automateを効率的に習得したい方へ
当サイトの情報を電子書籍用に読み易く整理したコンテンツを
買い切り950円またはKindle Unlimited (読み放題) で提供中です。

Word-A4サイズ:1500ページの情報量で
(実際のページ数はデバイスで変わります)
基本的な使い方から各トリガー/アクションの詳細な使い方、
頻出テクニック、実用例を紹介。(目次)
体系的に学びたい方は是非ご検討ください。
アップデートなどの更新事項があれば随時反映しています。(更新履歴)
なお購入後に最新版をダウンロードするには
Amazonへの問い合わせが必要です。